











")
Principiile FAIR (traducere după )
Introducere:
În ecosistemul eScience, provocarea de a oferi o utilizare optimă a datelor și a metodelor de cercetare este una complexă având actori multipli: cercetători care doresc să-și distribuie datele și interpretările; edituri specializate pe date care își oferă serviciile, software-ul, dar și creatorii de instrumente care oferă posibilitatea de a analiza datele și servicii de procesare; organismele de finanțare (public și private), care sunt din ce în ce mai interesate de o Gestionare a Datelor corespunzătoare, dar și o comunitate a datelor științifice care exploatează, integrează și analizează rezultatele pentru a face pași spre noi descoperiri. Analiza computațională pentru a descoperi structuri inteligibile în seturi de date masive interconectate devine o rutină în activitatea de cercetare. A pune la dispoziție date interpretabile de mașini ca principal substrat pentru Descoperirea Cunoașterii și pentru ca aceste procese de eScience să meargă fără impedimente și sustenabil este una din Cele mai Mari Provocări pentru eScience.
În ianuarie 2014, reprezentanții unui palier a părților interesate la solicitarea Centrului Olandez pentru eScience și a DTL - Dutch Techcentre for the Life Sciences în Leiden, Olanda, gazdă fiind Centrul Lorenz pentru a gândi și dezbate despre cum poate fi propulsat mai departe ecosistemul. Din aceste discuții, a apărut ideea că prin definirea și diseminarea largă a unui set minim de principii directoare și practici aprobate de comunitate, furnizorii de date și consumatorii acestora - mașini și oameni - ar putea să descopere, acceseze și interopereze mai ușor, dar și să reutilizeze mai inteligent prin citarea făcută corespunzător a unei vaste cantități de informații care este generată de știința contemporană care este concentrată pe date. Aceste principii și practici simple ar trebui să permită a paletă largă de comportamente integrative și exploratorii și să sprijine o gamă largă de opțiuni din domeniul tehnologiei și implementări așa cum este Internet Protocol la nivelul său primar - „talia” clepsidrei - care permite crearea unei game largi de instrumente pentru furnizarea, consumul și vizualizarea pe Internet.
2. Context
Este important să se remarce că acest document este un „ghid către datele conforme FAIR”, nu este o „specificație”. Compilarea principiilor directoare FAIR pentru acest document a evitat în mod conștient opțiunile de implementare tehnică. [Principiile directoare FAIR] minime sunt menite să ghideze implementatorii mediilor de date conforme FAIR verificându-se dacă opțiunile de implementare proprii oferă datele în acord. În Notele explicative și în anexe sunt oferite niște explicații și îndrumări care nu obligă la o anumită viziune FAIR asupra datelor sau ce este un depozit pentru date după tipicul FAIR („Data FAIRport”).
3. FAIR pentru mașini, dar și pentru oameni
În eScience se pot distinge două substraturi separate clar în ceea ce privește descoperirea cunoașterii.
- Datele în sine care sunt dincolo de capacitatea de analiză a intelectului uman și
Explicitome(înseamnă tot ce am explicat în text, baze de date și orice alt format existent).
În esență, eScience este că, fie interconectarea funcțională a datelor existente ori combinația acestora cu noile seturi de date „relativ reduse” ca dimensiune, conduce către noi înțelegeri. Un pas esențial este „recunoașterea structurilor” din date, care este urmat de un studiu uman „conformațional” al Explicitomului pentru a raționaliza structurile și pentru a determina care sunt ipotezele testabile. Desigur, acestea este un proces ciclic prin natura sa, dar analiza computațională a seturilor de date masive, dispersate de la crearea lor și care se modifică în timp, constituie o fază crucială în orice proces eScience.
Acestea sunt sintetizate ca „Fațete” FAIR: - Datele trebuie să fie Regăsibile - Datele trebuie să fi Accesibile - Datele trebuie să fie Interoperabile - Datele trebuie să fie Reutilizabile.
Evident, aceste Fațete FAIR sunt legate, dar tehnologic, cumva, independente una de cealaltă, putând fi implementate în orice combinație, incremental pe măsură ce evoluează furnizorii de date și FAIRport-urile evoluează către niveluri mai mari de claritate (FAIR-ness). Astfel, pragul de intrare pentru producătorii de date FAIR, pentru edituri și pentru cei care le întrețin, este menținut cât mai jos posibil iar furnizorii fiind încurajați să crească treptat numărul de Fațete FAIR cu care sunt armonizați.
În acest sens, scopul acestui document nu este să definești și nici nu sugerează nicio implementare tehnologică pentru niciuna dintre aceste fațete, ci să definească caracteristicile, normele și practicile pe care le prezintă sursele de date, instrumentele și infrastructurile pentru a fi considerate a fi „FAIR”, iar atingerea conformității cu aceste principii nu poate fi atinsă cu o largă varietate de tehnologii și implementări.
Principiile directoare pentru datele FAIR
Pentru toate părțile implicate în Gestionarea Datelor, fațetele FAIR descrise mai jos oferă un ghidaj incremental în ceea ce privește cum pot beneficia pentru a merge mai departe către obiectivul final de a avea toate referințele leagate de Obiectele de Date (Meta-datele și chiar Elementele de Date în sine) rezolvabile atât pentru mașini, cât și pentru oameni.
Prin adoptarea tuturor fațetelor FAIR, Obiectele Date devin pe deplin: Regăsibile, Accesibile, Interoperabile și Reutilizabile.
Definiții
- Un Concept este definit ca o „unitate de gând” la care ne referim în formatele noastre digitale [1].
- Un Obiect de Date se definește pentru scopul principiile de mai jos: Un Element de date identificabile cu elemente de date + Metadate + un Identificator [2]
- Atunci când folosim aici termenul de (Meta)date, avem în intenție să indicăm faptul că principiul este adevărat pentru Metadate cât și pentru Elementele de Date colectate din Obiectul de Date, dar principiul se poate aplica independent pentru fiecare dintre ele [3].
Principiile directoare FAIR pentru date
-
Pentru a fi Regăsibil oricare Obiect de Date ar trebui să fie identificabil unic și persistent [4] 1.1 Același Obiect de Date ar trebui să fie re-găsibil în orice moment, astfel că Obiectele de Date ar trebui să fie persistente, cu accent pe metadatele lor, [ [4], Principiul 4 din Declarația comună privind principiile citării datelor - final și Principiul 6 al aceleiași declarații ] 1.2 Un Obiect de Date ar trebui să conțină cel puțin metadate la un nivel de bază care să fie acționabile de mașini care să permită acestuia să se distingă de alte Obiecte de Date vezi Principiul 5 al Declarației comune privind principiile citării datelor - final 1.3 Identificatorii oricărui concept utilizat în Obiectele de Date ar trebui să fie Unici și Pesistenți [5 și Principiile 4 și 6 ai Declarației comune privind principiile citării datelor]
-
Datele sunt Accesibile în sensul că pot fi obținute întotdeauna de către mașini și de oameni deopotrivă 2.1 Dacă este oferit nivelul de autorizare corespunzător [6] 2.2 Printr-un protocol bine definit [7 și Principiul 5 din Declarația comună privind principiile citării datelor - final] 2.3 Astfel, mașinile și oamenii vor putea să evalueze fiecare gradul de accesibilitate a fiecărui Obiect de Date.
-
Obiectele Date pot fi Interoperabile doar dacă: 3.1 (Meta) datele sunt acționabile și de mașini [8] 3.2 Formatele de (meta) date utilizează vocabulare distribuite și/sau ontologii [9] 3.3 (Meta) datele din Obiectul de Date ar trebui să fie ușor de citit din punct de vedere sintactic și citibil de mașini ca semantie [10]
-
Pentru ca Obiectele de Date să fie Reutilizabile, criteriile suplimentare pe care trebuie să le întrunească sunt: 4.1 Obiectele de Date ar trebui să respecte principiile 1-3 4.2 (Meta)datele ar trebui să fie îndeajuns de bine descrise și bogate ca să fie interconectate și integrate automat (sau cu eform minim din partea omului) cu alte surse de date [11 și Principiile 7 și 8 ale Declarației comune privind principiile citării datelor - final] 4.3 Obiectele de Date ar trebui să se refere la sursele lor întrebuințând metadate îndeajuns de bogate și pentru origine pentru a permite o citate corespunzătoare [ Principiile 1 - 3 ale Declarației comune privind principiile citării datelor ]
[1] Urmăm definițiile și argumentele Triunghiului lui Ogden/Richard și teoria înțelesurilor pentru concept, simbol și definițiile pentru înțeles: vezi . Conceptul, în sine, nu este un Obiect Digital, dar oricare simbol care face referință la aceste în computere este un Obiect Digital. Cuvintele limbii, URI-urile, URL-urile și alți identitificatori sunt cu toate simboluri care se referă la concept.
[2] Vezi cum arată un exemplar în anexa 4 Propunem termenul de „Obiect de Date” pentru a ne referi la combinația de elemente de date + metadatele lor + un identificator unic. Aceste obiecte sunt de o complexitate arbitrară și pot să apară în multe forme și sub diferite sintaxe.
[3] Recunoaștem distinct faptul că depozitele de Obiecte de Date care au metadate FAIR pentru Elementele de Date care nu sunt (încă) FAIR (nu urmează principiul asigurării liziblității și pentru mașini, așa cum sunt imaginile, materialele video sau textele înregistrate) sunt foarte valoroase, dar ar trebui să fie diferite de depozitele cu elemente care pot fi citite de mașini și care beneficiază de un management de înaltă calitate (bineînțeles că se înțelege că are metadate FAIR atașate). Astfel, metadatele FAIR se impun iar elementele de date FAIR trebuie să fie „scopul final”.
[4] Persistența este o proprietate a organizării. Efectiv este o obligație formală sau informală prin care o organizație garantează că ceva va fi întreținut. Astfel, politica organizațională privind persistența ar trebui să fie explicită și publică. Propunem FAIRports pentru că își declară clar garanțiile privind persistența și caută mecanismele de replicare și back up a propriilor resurse ori de câte ori este posibil.
[5] În acest moment sunt dezbateri aprige asupra a ceea ce constituie un identificator „persistent”. Acronimul PID este evitat în mod conștient aici pentru că ar putea avea conotații ce implică implementări proprietare. Propunem să fie permiși mai mulți identificatori în mediile de publicare a datelor FAIR atâta vreme cât un identificator trimite către un singur concep iar editorul oferă o politică și o descriere clare asupra tuturor granțiilor posibile că există un mecanism care să rezolve identificatorul către locația/înțelesul corect. Este evident faptul că identificatorii folosiți la nivel „local”, care nu pot fi asociați automat unei scheme de identificatori elaborată și adoptată public de comunitate, nu sunt FAIR. Editorul de date care alege o schemă de identificare „proprietară”, va trebui să ofere o corespondență potrivită și corectă care să fie considerată FAIR.
Organizațiile care oferă identificatori persistenți (i.e. „autorități”), ar trebui să-și publice clar politicile care guvernează persistența criteriilor acestor identificatori. Aceste politici trebuie să fie lizibile și pentru mașini.
[6] Mai ales pentru utilizarea comercială a datelor FAIR, companiile trebuie să aibe o înțelegere clară și o poziție din punct de vedere legal privind abilitatea de a folosi datele. Datele care nu sunt sub o licență, chiar dacă par „deschise” în mintea celor mai mulți oameni de știință, vor fi evitate de majoritatea companiilor mari din pricina riscurilor legale ridicate. Înțelegem excepțiile de la Acces Deschis deplin pentru anumite date (de exemplu, din motive de protejare a vieții private sau pentru protecția pacienților). Astfel, noi înțelegem o licențiere de la caz la caz a Obiectelor de Date (sau chiar a unor elemente de date individuale în interiorul acestora), ca o cheie către publicarea datelor ca FAIR.
Licențele și condițiile pentru utilizarea Obiectelor Date (în mediul academic și/sau privat/comercial), ar trebui să fie bine descrise. Astfel de licențe pot fi referite prin identificatori persistenți la fel de bine ca și în cazul fragmentelor de metadate din Obiectele de Date. Într-un ritm accelerat, comunitatea FAIRport va pune la dispoziție și va recomanda licențe standard din care se poate alege. Comunitatea FAIRport recomandă viguros publicarea datelor în Acces Deschis deplin oriunde acest lucru este posibil. Este de așteptat ca majoritatea „autorităților” care sprijină FAIRports să facă solicitarea ca excepțiile de la Acces Deschis să fie bine argumentate. (vezi Anexa 3). (o listă de licențe) Jan Velterop/John Wilbanks.
[7] A pune datele „pe web” nu este îndeajuns. Pentru a fi cu adevărat interoperabile și reutilizabile, Obiectele Date nu numai că ar trebui să fie corect licențiate, dar metodele de a le accesa și/sau descărca, ar trebui să fie bine documentate și preferabil să fie deplin automatizate folosindu-se protocoale bine stabilite.
[8] în eScience, lizibilitatea datelor pentru mașini este de neevitat. Metadatele fiind citibile de către mașini, vor transforma Obiectul de Date într-unul și mai interoperabil și ușurează interconectarea funcțională și analiza într-un context mai larg, dar nu este o condiție preliminară pentru publicarea datelor ca FAIR. Unele elemente de date, de exemplu, imaginile și „datele brute” pot fi oricând expuse pentru a fi procesate de mașini. Publicarea ca metadate FAIR este de o valoare înaltă în sine.
[9] Când sistemele adoptate de comunitate și terminologia din sfera publică nu sunt disponibile, de exemplu din motivele descrise în nota explicativă 5, sau pentru că Obiectele de Date conțin concepte care nu au fost descrise în niciun vocabular public sau în vreo ontologie cunoscute furnizorului, acesta ar trebui să creeze un vocabular terminologic propriu pe care să-l publice în zona publică deschizându-l preferabil într-o formă citibilă de mașină. Vocabularul sau ontologia care obligă fiecare element de date strict, ar trebui să fie identificabil de însuși câmpul sau de metadate asociate Obiectului de Date. Pentru câmpurile care nu sunt stricte, ori de câte ori este posibil, tipul valorii câmpului ar trebui să fie adnotat folosind un vocabular sau o ontologie accesibilă public. Această adnotare ar trebui să fie clară în metadatele Obiectului de Date.
[10] Sintaxa și semantica modelelor și formatelor de date folosite pentru (Meta)datele din Obiectele de Date, ar trebui să fie ușor de identificat și de folosit, ușor de parcurs sau de tradus de către mașini. Precum în cazul vocabularelor și a schemelor de identificare, o largă varietate de formate de date (de la foi de calcul care expune URI-uri precum RightField sau OntoMaton, la RDF-uri bogate), ar putea fi conforme FAIR. Este evident că oricare protocol de citire sau de traducere este supus erorilor iar situația ideală este de a restricționa publicarea datelor conforme FAIR la cât mai puține formate și standarde adoptate de comunitate. Totuși, dacă un furnizor poate dovedi faptul că un model/format de date alternativ este ușor de citit pentru unul dintre formatele FAIR adoptate de comunitate, nu există niciun motiv pentru ca un astfel de format să nu fie considerat a fi FAIR. Câteva tipuri de date pur și simplu nu pot fi „încadrate” în formatele existente iar în acest caz, doar părți ale elementelor de date pot fi citite. FAIRport-urile vor oferi din ce în ce mai multe îndrumări și asistență în astfel de cazuri.
[11] Metadatele unui Obiect de Date ar trebui să fie îndeajuns de bogate pentru ca o mașină sau un operator uman, la momentul descoperirii lor să facă o alegere informată dacă este bine să folosească sau nu acel Obiect de Date în contextul propriilor analize. Metadatele conținute în Obiectul de Date ar trebui să informeze consumatorul despre licența acestor elemente de date; aceste metadate ar trebui să fie citibile de mașină pentru a ușura recoltarea automată a datelor menținând o atribuire corespunzătoare. Metadatele conținute în Obiectul de Date ar trebui să indice orice politică de acces pentru ca cei care le consumă să determine la care dintre componentele datelor este permis accesul. Metadatele din Obiectul de Date ar trebui să informeze despre protocolul de autentificare care conduce la acces dacă acest lucru se aplică. Mai mult, în eScience, acolo unde recunoașterea structurilor în seturi de date interconectate funcțional sau integrate de „mari dimensiuni”, devine modul de operare curent, stabilirea originii este cheia. În cazul în care se conturează o structură din algoritmii de analiză a datelor, studiile de raționalizare și cele de confirmare întreprinse în sursele de date de la bază, constituie următorul pas crucial. Dacă se pierde originea Elementelor de Date, adică Obiectul de Date și mai departe resursele care le compun (text citibil pentru oameni, baze de date, fișiere cu date brute), cercetătorii nu vor putea să caute dovezile pentru ceea ce indică structurile detectate pentru a ajunge la o ipoteză testabilă.
Notă finală: Recunoaștem că este posibil să implementăm oricare dintre aceste sub-fațete fără a le implementa pe toate. Aici oferim ceva îndrumări de pornire privind cum să îmbunătățești gradual nivelul de compatibilitate cu principiile FAIR pentru Obiectele de Date.
Facet-I-syn: Metadatele sunt introduse într-un format care poate fi citit de o mașină; i.e. există un standard deschis pentru formatul pentru care se poate scrie cod de citire.
Metadatele ar trebui să se refere la schema care este folosită.
Facet-I-sem: Metadatele au avantajul vocabularelor controlate distribuite sau a ontologiilor permițând corespondențe ale câmpurilor de metadate din resurse disparate (indiferent de sintaxa lor care este în fiecare dintre aceste depozite).
Metadatele ar trebui să se refere la vocabularele și ontologiile care sunt folosite.
Facet-I-data: Ori de câte ori este posibil, datele ar trebui să fie oferite într-un format care să poată fi citit de mașină; i.e. adică să fie un format standardizat și deschis pentru care cod de citire să poată fi scris.
Structurile de date ar trebui definite după scheme publice, documentate și acolo unde este cazul citibile și pentru mașini.
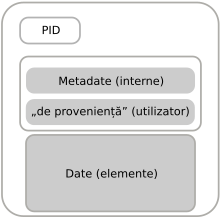
Anexa 2: Exemplul unei perspective modulare privind Datele și Obiectele de Date
În nucleul proceselor de formatare și publicare a datelor FAIR există o perspectivă coerentă asupra a ce sunt datele și cum sunt acestea structurate. Perspetiva valoarii adăugate (eScience) a datelor FAIR este în primul și în primul rând „FAIR pentru mașini”. Lizibilitatea pentru oameni ca „derivat” al unei bune formatări și definiri a datelor citibile de mașină este evident crucială pentru interpretarea finală.
De fapt, datele FAIR vor îmbunătăți lizibilitatea pentru oameni cum ar fi în cazul termenilor care dau numele unor concepte și care pot fi prezentate utilizatorilor umani în propria limbă, bazându-ne pe tabelele ARTA (Also Referred To As) ale mașinilor de traducere care rezolvă identificatorii către termenii lingvistici.
Așadar, vedem aici datele inițiate în „format digital”. Din această perspectivă „Datele” și „Metadatele” se deosebesc doar prin „ce reprezintă” fiecare și „la ce sunt folosite”, nu prin formatul tehnic. În final, in eScience, software-ul care prelucrează date este inseparabil de acestea și de dragul simplității, vom trata „codul” ca „date executabile” pentru a servi acest document.
- Datele folosite de mașini sunt în sinea lor „digitale” iar fiecare Obiect de Date (definit în principiile FAIR), este un „Obiect Digital” în natura sa.
- Unul din cele mai mici Obiecte de Date dintr-un aranjament de date FAIR este un identificator uni care trimite la un concept (un unic gând), de vreme ce un concept în sine nu este un Obiect Digital. [referință către triunghiul lui Ogden, vezi principiile FAIR, nota explicativă 1]
- Identificatorii pot fi proiectați pentru computere sau pentru oameni, iar într-un context de date FAIR, recomandăm cel puțin un identificator permanent care să poată fi rezolvat de o mașină (PID) pentru fiecare concept folosit într-un Obiect de Date.
- PID-uri multiple și alte ID-uri pentru același concept sunt un lucru obișnuit și trebuie acceptat, dar ID-urile FAIR trebuie să fie garantate pentru a face legături către un singur concept.
- Tabelele de legături și serviciile de corespondențe care gestionează multipli identificatori (permanenți) sunt acceptate în datele FAIR și ar trebi să fie oferite acolo unde sunt necesare.
- Elementele de Date sunt definire ca date în sine și astfel sunt atât de diferiți din punct de vedere tehnic de metadatele lor.
- Unul dintre cele mai mici „Elemente de Date” este o singură asociere dintre două concepte.
- Fiecare Obiect de Date FAIR (chiar și o simplă aserțiune despre o singură asociere) ar trebui să aibe un PID (pentru Obiectul de Date ca întreg) și un set minim de metadate „despre” obiectul de Date în sine
- Elemente de date multiple care se pot identifica pot să aibe aceleași metadate și același PID și să formeze un Obiect de Date FAIR (de exemplu un set de imagini sau o colecție mică de date cu valori ce exprimă gene)
- Elemente de Date individuale care pot fi identificate, pot fi folosite separat, citate și distribuite ca noi Obiecte de Date care au un PID nou și care conțin îndeajuns de multe metadate din Obiectul de Date original cât să se poată ajunge înapoi la ele și care pot fi citate ele însele sau ca „derivate din” Obiectul de Date original mai mare.
- Obiectele de Date sunt Obiecte Digitale „modulare” și „recurente” care se pot extinde de la o singură asociere între două concepte la întreaga bază de date sau lux de lucru care are mai multe module.
- Obiectele de Date FAIR pot avea metadate definite de utilizator care să fie bogate sau minimale (vezi imaginea de mai sus) și pot avea până la câteva milioane de elemente de date identificabile.
Anexa 3: Din ce este alcătuit un FAIRport de date? (BM, PG, MW)
De vreme ce FAIR nu este o marcă înregistrată, propunem să lăsăm decizia de a considera depozitele digitale drept FAIRports (meta date sau metadate + date care pot fi separate), „autorităților” așa cum sunt nodurile ELIXIR/Hub-ul, NIH sau SciELO.
Propunem definirea unui candidat FAIRport ca fiind oricare depozit de date orientat către consumul mașinilor care: - Conține Obiecte de Date FAIR (a se evalua de către autoritatea care stabilește conformitatea) - Oferă aceste Obiecte de Date sub o politică bine stabilită pentru accesibilitate și reutilizare - Beneficiază de o descriere deplină și deschisă pentru toate tehnologiile, vocabularele controlate și formatele utilizate.
Propunem ca fiecare Persoană de Încredere din fiecare disciplină științifică: - Să definească „autoritățile” pentru fiecare „categorie semantică” a conceptelor pentru care se fac referințe, de regulă în Obiectele de Date din propriile discipline, - Să-și definească propriile criterii minimale pentru a califica Obiectele de Date ca fiind FAIR - Evaluare individuală a FAIRport-urilor de date urmărind criteriile stabilite, - Introducerea unei mărci de calitate vizibile [depozit de încredere] pentru FAIRport-urile care sunt conforme - Publicarea în Depozite Deschise (preferabil să fie FAIR ele însele) a lucrurilor care sunt așteptate din partea FAIRport-ului pentru constituirea indexului și pentru ca acestea să primească marca de calitate,
Noi propunem să fie luate în considerare următoarele „niveluri” pentru FAIRport-uri sau chiar pentru Obiectele de Date care sunt conținute în ele (cu alte cuvinte, un FAIRport ar putea să conțină Obiecte de Date cu diferite „niveluri de conformitate cu FAIR”)(vezi figura).
Nivelul 1: Fiecare Obiect de Date are un PID și metadate FAIR incluse (în esență, fiind unul „static”). Nivelul 2: Ficare Obiect de Date are metadate „definite de utilizator” (care sunt actualizate) pentru a oferi o descriere a originii foarte bogată urmând formatul FAIR pentru date, ce s-a petrecut cu acesta, pentru ce a fost utilizat, etc., toate acestea putând fi considerate ca adnotări FAIR extinse. Nivelul 3: Elementele de Date însele din Obiectul de Date sunt tot FAIR, dacă vorbim de nivelul tehnic, dar nu sunt pe deplin cu Acces Deschis și nici Reutilizabile fără restricții (de exemplu, date a pacienților sau date proprietare). Nivelul 4: Metadatele ca și elementele de date sunt conforme pe deplin cu FAIR sub o licență bine definită. (Datele care nu sunt licențiate și care sunt considerate de posesor a fi „publice” vor fi excluse din proiectele de integrare, cum ar fi în cazul companiilor farmaceutice).

Anexa 4: Scenarii de utilizare și inițiative înrudite
(adaptat după contribuțiile originale ale lui Michael și Juns)
În știința axată pe date, cercetătorii, dar în continuă creștere și mașinile, au nevoie mai întâi de toate să poată găsi/descoperi datele care prezintă caracteristici interesante pentru care vor fi utilizate linkuri, metadate, precum și elemente/conținuturi de date.
Din momentul în care sunt descoperite, mașinile au nevoie să acceseze/descarce datele de interes (i.e. să obțină o copie a conținuturilor într-un format). Următorul pas pentru cercetători este să decidă să „arunce un ochi pe ele” folosind propriile computere pentru a începe să reutilizeze/analizeze datele interesante din lista extinsă obținută din „rețeaua de date” la care trebuie să aibe acces beneficiind de un flux de instrumente de procesare facil: a. Informații ale unor metadate bogate privind Obiectele de Date de interes b. Răspunsul la o întrebare folosind mai multe instrumente sau un grup c. Agregare de seturi de date și aplicarea unor analize statistice d. Validarea corectitudinii/autenticității datelor e. Oglindirea/schimbul de date dintre depozite (sustenabilitate prin redundanță) f. Repetarea/reproducerea datelor generarea/analiza g. Link-uirea sau integrarea datelor pentru a avea o perspectivă coerentă h. Obținerea de probe la niveluri multiple pentru a indica suportul pentru o ipoteză testabilă i. Citatea întregului Obiect de Date sau a unor elemente de date individuale (acolo unde este posibil) pentru a fi creditat. j. În oricare moment să poți obține „conglomeratul de date citat” așa cum era la momentul citării (este cazul seturilor de date care cresc dinamic, așa cum este un flux Twitter sau blogul unui pacient sau orice date ca rezultate a efectelor).
Pentru toți acești pași de flux pentru eScience (și mulți alții care pot fi imaginați), următoarele caracteristici a unor date corecte ca substrat primar pentru descoperirea de cunoaștere asistată de mașini sunt: - o descriere bogată (în format citibil de mașină) - persistență (disponibilitate la cerere) - să existe scheme de identificatori și citare - să fie accesibile și disponibile într-o varietate de formate - să fie interoperabile implicând folosirea standardelor/ghidurilor - să fie gata de a fi interconectate iar acolo unde este necesar să fie integrate - să existe o schemă de licențiere pentru fiecare obiect de date - să fie oferit controlul utilizatorului - să fie reutilizabile - să se poată identifica originea - să existe mecanisme de asigurare a calității - să permită integrarea de conținut introdus de utilizatori
Principiile FAIR (Regăsibile, Accesibile, Interoperabile și Reutilizabile) au fost proiectate având în minte acești pași ai fluxului de cercetare: - să fie regăsibile (F) sau ușor de descoperit datele și metadatele trebuie să fie bogat descrise pentru a permite o căutare bazată care să folosească atributele. - să fie accesibile cât mai larg (A), datele și metadatele să poată fi obținute într-o mare varietate de formate care să fie permisibile mașinilor și oamenilor folosindu-se identificatorii permanenți - să fie interoperabile (I), descrierea elementelor de metadate ar trebui să urmeze ghidurile elaborate de comunitate care folosesc un vocabular deschis și bine definit. - pentru a fi reutilizabile (R), descrierea elementelor de metadate care sunt esențiale, recomandate și opționale, ar trebui să fie procesabile și verificabile ușor de către mașini; utilizarea ar trebui să fie ușoară iar datele să fie citabile pentru a susține distribuirea datelor și recunoașterea valorii datelor.
(adoptată din iunie, făcând referințe la )
Datele care sunt FAIR sunt totodată o cale de a sprijini cele „7-R-uri”, care au motivat inițial crearea Obiectelor de Cercetare. Cei 7-R se circumscriu principiilor FAIR dar fac parte și din activitățile științifice și de cercetare în care Obiectele de Cercetare joacă un rol cheie.
Referința este 7-R (v1): De ce Datele Interconectate nu sunt îndeajuns pentru cercetători (2012). DOI:10.1016/j.future.2011.08.004
- Reutilizabile
- Redirectabile
- Repetabile
- Reproductibile
- Redabile
- Referențiabile
- Respectabile
Vezi și
Vom elabora pe implementarea principiilor FAIR prin activități legate care să vină sprijine o știință de înalt nivel, care să permită replicarea, să permită accesul mașinilor așa cum sunt Obiectele de Cercetare, BioSharing, Force11 și FAIRdom (modele FAIR SB). Vedem principiile FAIR ca pe o deschidere solidă care sprijină multe practici inovative asociate cu eScience, distribuirea datelor și reutilizarea acestora, gestionarea datelor și a software-ului aferent, practicile de capturare a datelor în proiectarea studiilor și a modelelor multiscalare, a vizualizărilor și a citării corespunzătoare a datelor și a metricilor alternative.
Note de traducere
Numele de FAIR, acest acronim este un joc de cuvinte, care se poate traduce în spirit: „clar” cu nuanțarea de „citeț”. Despre acest aspect vorbește corpul de principii enunțate.
Traducerea termenului de „share” este „a distribui”. Am renunțat la calchierea „a șerui”, care încet, încet își face loc în româna vorbită.
Termenul de „patterns” a fost tradus ca „structuri”.
Data Stewardship este tradus ca „gestionarea datelor.
Conceptul de „cited data cluster” a fost tradus ca și „conglomerat de date citat”.
Termenul de „persistent identifier” a fost tradus aici ca „identificator persistent”. La fel a fost tradus și în Declarația comună privind principiile citării datelor
Termenul de „parsing” a fost tradus ca „citire” pentru că se apropie de acțiunea exercitată de un agent software asupra unor date. A analiza a fost decăzut ca sens în acest caz pentru că ar implica operațiuni suplimentare din partea agentului.